

基于用户投票的排名算法(五):威尔逊区间
迄今为止,这个系列都在讨论,如何给出"某个时段"的排名,比如"过去24小时最热门的文章"。
但是,很多场合需要的是"所有时段"的排名,比如"最受用户好评的产品"。
这时,时间因素就不需要考虑了。这个系列的最后两篇,就研究不考虑时间因素的情况下,如何给出排名。
一种常见的错误算法是:
得分 = 赞成票 - 反对票
假定有两个项目,项目A是60张赞成票,40张反对票,项目B是550张赞成票,450张反对票。请问,谁应该排在前面?按照上面的公式,B会排在前面,因为它的得分(550 - 450 = 100)高于A(60 - 40 = 20)。但是实际上,B的好评率只有55%(550 / 1000),而A为60%(60 / 100),所以正确的结果应该是A排在前面。
Urban Dictionary就是这种错误算法的实例。
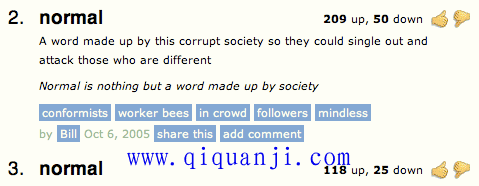
另一种常见的错误算法是
得分 = 赞成票 / 总票数
如果"总票数"很大,这种算法其实是对的。问题出在如果"总票数"很少,这时就会出错。假定A有2张赞成票、0张反对票,B有100张赞成票、1张反对票。这种算法会使得A排在B前面。这显然错误。
Amazon就是这种错误算法的实例。

那么,正确的算法是什么呢?
我们先做如下设定:
(1)每个用户的投票都是独立事件。
(2)用户只有两个选择,要么投赞成票,要么投反对票。
(3)如果投票总人数为n,其中赞成票为k,那么赞成票的比例p就等于k/n。
如果你熟悉统计学,可能已经看出来了,这是一种统计分布,叫做"二项分布"(binomial distribution)。这很重要,下面马上要用到。
我们的思路是,p越大,就代表这个项目的好评比例越高,越应该排在前面。但是,p的可信性,取决于有多少人投票,如果样本太小,p就不可信。好在我们已经知道,p是"二项分布"中某个事件的发生概率,因此我们可以计算出p的置信区间。所谓"置信区间",就是说,以某个概率而言,p会落在的那个区间。比如,某个产品的好评率是80%,但是这个值不一定可信。根据统计学,我们只能说,有95%的把握可以断定,好评率在75%到85%之间,即置信区间是[75%, 85%]。
这样一来,排名算法就比较清晰了:
第一步,计算每个项目的"好评率"(即赞成票的比例)。
第二步,计算每个"好评率"的置信区间(以95%的概率)。
第三步,根据置信区间的下限值,进行排名。这个值越大,排名就越高。
这样做的原理是,置信区间的宽窄与样本的数量有关。比如,A有8张赞成票,2张反对票;B有80张赞成票,20张反对票。这两个项目的赞成票比例都是80%,但是B的置信区间(假定[75%, 85%])会比A的置信区间(假定[70%, 90%])窄得多,因此B的置信区间的下限值(75%)会比A(70%)大,所以B应该排在A前面。
置信区间的实质,就是进行可信度的修正,弥补样本量过小的影响。如果样本多,就说明比较可信,不需要很大的修正,所以置信区间会比较窄,下限值会比较大;如果样本少,就说明不一定可信,必须进行较大的修正,所以置信区间会比较宽,下限值会比较小。
二项分布的置信区间有多种计算公式,最常见的是"正态区间"(Normal approximation interval),教科书里几乎都是这种方法。但是,它只适用于样本较多的情况(np > 5 且 n(1 − p) > 5),对于小样本,它的准确性很差。
1927年,美国数学家 Edwin Bidwell Wilson提出了一个修正公式,被称为"威尔逊区间",很好地解决了小样本的准确性问题。
在上面的公式中,表示样本的"赞成票比例",n表示样本的大小,
表示对应某个置信水平的z统计量,这是一个常数,可以通过查表或统计软件包得到。一般情况下,在95%的置信水平下,z统计量的值为1.96。
威尔逊置信区间的均值为
它的下限值为
可以看到,当n的值足够大时,这个下限值会趋向。如果n非常小(投票人很少),这个下限值会大大小于
。实际上,起到了降低"赞成票比例"的作用,使得该项目的得分变小、排名下降。
Reddit的评论排名,目前就使用这个算法。
[参考文献]
* How Not To Sort By Average Rating
(完)
原文链接:https://www.qiquanji.com/post/6908.html
本站声明:网站内容来源于网络,如有侵权,请联系我们,我们将及时处理。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。