

第671页
-
基于用户投票的排名算法(五):威尔逊区间
迄今为止,这个系列都在讨论,如何给出"某个时段"的排名,比如"过去24小时最热门的文章"。 但是,很多场合需要的是"所有时段"的排名,比如"最受用户好评的产品"。 这时,时间因素就不需要考虑了。这个系列的最后两篇,就研究不考虑时间因素的情况下,如何给出排名。 一种常见的错误算法是: 得分 = 赞成票 - 反对票 假定有两个项目,项目A是60张赞成票,40张反对票,项目B是550张赞成票,450张反对票。请问,谁应该排在前面?按照上面的公式,B会排在前面,因为它的得分(550 - 450 = 100)...
-

基于用户投票的排名算法(六):贝叶斯平均
(这个系列实在拖得太久,今天是最后一篇。) 上一篇介绍了"威尔逊区间",它解决了投票人数过少、导致结果不可信的问题。 举例来说,如果只有2个人投票,"威尔逊区间"的下限值会将赞成票的比例大幅拉低。这样做固然保证了排名的可信性,但也带来了另一个问题:排行榜前列总是那些票数最多的项目,新项目或者冷门的项目,很难有出头机会,排名可能会长期靠后。 以IMDB为例,它是世界最大的电影数据库,观众可以对每部电影投票,最低为1分,最高为10分。 系统根据投票结果,计算出每部电影的平均得分。然后,再根据平均得分,排出...
-

-

贝叶斯推断及其互联网应用(三):拼写检查
(这个系列的第一部分介绍了贝叶斯定理,第二部分介绍了如何过滤垃圾邮件,今天是第三部分。) 使用谷歌的时候,如果你拼错一个单词,它会提醒你正确的拼法。 比如,你不小心输入了 seperate。 谷歌告诉你,这个词是不存在的,正确的拼法是 separate。 这就叫做"拼写检查"(spelling corrector)。有好几种方法可以实现这个功能,谷歌使用的是基于贝叶斯推断的统计学方法。这种方法的特点就是快,很短的时间内处理大量文本,并且有很高的精确度(90%以上)。谷歌的研发总监 Peter No...
-

-

泊松分布与美国枪击案
去年12月,美国康涅狄格州发生校园枪击案,造成28人死亡。 资料显示,1982年至2012年,美国共发生62起(大规模)枪击案。其中,2012年发生了7起,是次数最多的一年。 去年有这么多枪击案,这是巧合,还是表明美国治安恶化了? 前几天,我看到一篇很有趣的文章,使用"泊松分布"(Poisson distribution),判断同一年发生7起枪击案是否巧合。 让我们先通过一个例子,了解什么是"泊松分布"。 已知某家小杂货店,平均每周售出2个水果罐头。请问该店水果罐头的最佳库存量是多少?...
-

TF-IDF与余弦相似性的应用(一):自动提取关键词
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。 有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到? 这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。 让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖...
-

TF-IDF与余弦相似性的应用(三):自动摘要
有时候,很简单的数学方法,就可以完成很复杂的任务。 这个系列的前两部分就是很好的例子。仅仅依靠统计词频,就能找出关键词和相似文章。虽然它们算不上效果最好的方法,但肯定是最简便易行的方法。 今天,依然继续这个主题。讨论如何通过词频,对文章进行自动摘要(Automatic summarization)。 如果能从3000字的文章,提炼出150字的摘要,就可以为读者节省大量阅读时间。由人完成的摘要叫"人工摘要",由机器完成的就叫"自动摘要"。许多网站都需要它,比如论文网站、新闻网站、搜索引擎等等。2007年,...
-
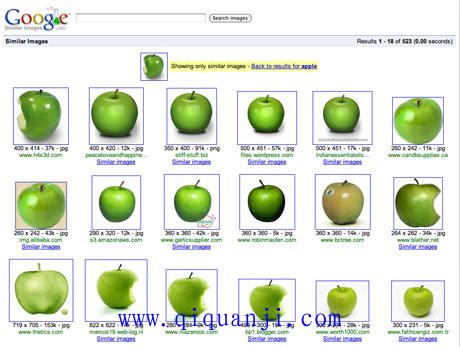
相似图片搜索的原理(二)
二年前,我写了《相似图片搜索的原理》,介绍了一种最简单的实现方法。 昨天,我在isnowfy的网站看到,还有其他两种方法也很简单,这里做一些笔记。 一、颜色分布法 每张图片都可以生成颜色分布的直方图(color histogram)。如果两张图片的直方图很接近,就可以认为它们很相似。 任何一种颜色都是由红绿蓝三原色(RGB)构成的,所以上图共有4张直方图(三原色直方图 + 最后合成的直方图)。 如果每种原色都可以取256个值,那么整个颜色空间共有1600万种颜色(256的三次方)。针对这1600...
-

TF-IDF与余弦相似性的应用(二):找出相似文章
上一次,我用TF-IDF算法自动提取关键词。 今天,我们再来研究另一个相关的问题。有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。 为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。 为了简单起见,我们先从句子着手。 句子A:我喜欢看电视,不喜欢看电影。 句子B:我不喜欢看电视,也不喜欢看电影。 请问怎样才能计算上面两句话的相似程度...



最新留言
说:asdasd
2023-05-26 10:48:03说:I
2023-04-07 09:22:25说:2366
2023-03-30 09:40:21说:1
2023-03-30 09:40:16说:6
2023-03-03 17:48:00说:发的太多人
2023-02-27 15:34:13说:1
2023-02-02 19:12:01说:我靠
2023-01-26 10:55:41