Tensorflow:基于LSTM的股票预测模型对股票的收盘价进行预测(Keras实现)
LSTM全称长短期记忆人工神经网络(Long-Short Term Memory),是对RNN的变种。
长短期记忆模型(long-short term memory)是一种特殊的RNN模型,是为了解决反向传播过程中存在梯度消失和梯度爆炸现象,通过引入门(gate)机制,解决了RNN模型不具备的长记忆性问题
传统的线性模型难以解决多变量或多输入问题,而神经网络如LSTM则擅长于处理多个变量的问题,该特性使其有助于解决时间序列预测问题。
先准备训练数据,我用的是用tushare获取的600673东阳光的数据,数据是csv格式,上传为附件(点击可以下载):
{kind=link}
全部代码如下(代码为全部代码,复制可以直接运行):
1. 导入需要用到的库
#import需要用到的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf
import tensorflow.keras from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Embedding, LSTM, SpatialDropout1D, SimpleRNN, GRU, Flatten
2.读入数据文件,加载到内存中
# 读入数据文件 df = pd.read_csv('./600673.csv', encoding='gbk') # 展示数据 df.head() # 显示DataFrame的前若干行,默认为5 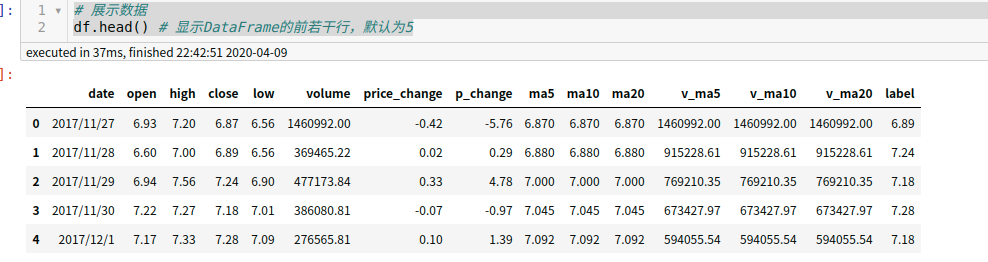{kind=link}
数据说明:
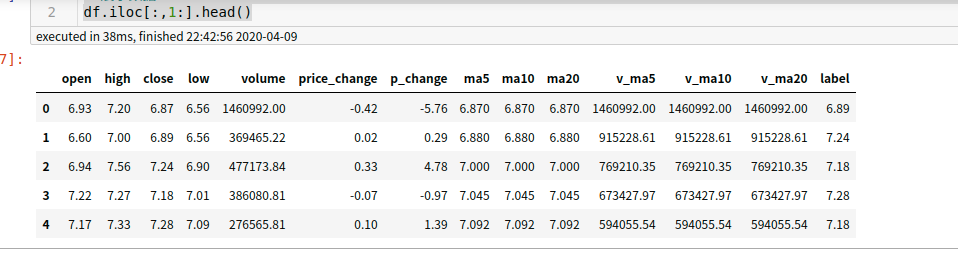
3. 对数据进行处理,去掉日期,因为日期对训练无用,已经按照日期排序了
data = df.iloc[:,1:].values # 展示数据 df.iloc[:,1:].head()
{kind=link}
4. 写个例子对数据进行处理,数据标准化,数据量纲不同,数值大小差别很大。数据中,有的为纯小数如0.98,有的数据动辄上万,两者不具有可比性,因此我们需要引入数据标准化。数据标准化处理主要包括数据同趋化和无量纲化处理。
数据标准化的方法有很多种,如:Min-max标准化、Z-score标准化等。
Min-max标准化公式为:新数据=(原始数据-最小值)/(最大值-最小值)
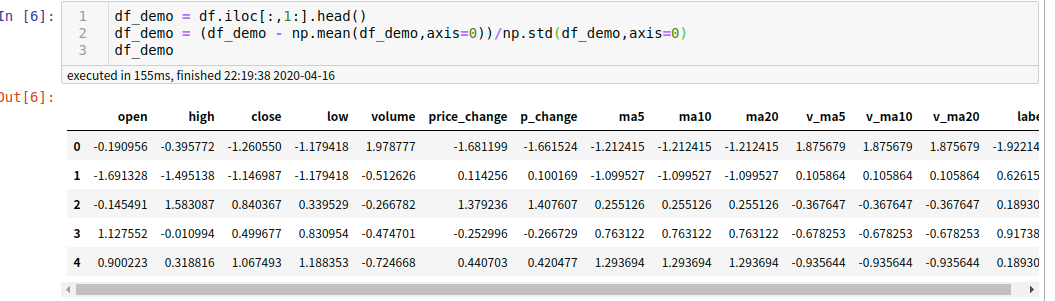
Z-score标准化公式为:新数据=(原始数据-均值)/ 标准差
本案例中采用的标准化方式为Z-score标准化,数据如下:
df_demo = df.iloc[:,1:].head() df_demo = (df_demo - np.mean(df_demo,axis=0))/np.std(df_demo,axis=0) df_demo
{kind=link}
下面是数据特征归一化:
LSTM对输入数据的规模很敏感,特别是当使用sigmoid(默认)或tanh激活函数时。需要将数据重新调整到0到1的范围(也称为标准化)。本实验使用scikit-learn库中的MinMaxScaler预处理类实现数据集的规范化
#获取Data中的数据,形式为数组array形式 data = df.iloc[:,1:].values #确保所有数据为float类型 data=data.astype('float32') # 特征的归一化处理 scaler = MinMaxScaler(feature_range=(0, 1)) scaled = scaler.fit_transform(data) print(scaled) 以上两种方法选择一个就好!
5. 数据集获取函数:
# 获取训练集 def get_train_data(time_step,train_begin,train_end): data_train=data[train_begin:train_end] y_ = data_train[time_step:train_end, 13] # mean, std = np.mean(data_test, axis=0), np.std(data_test, axis=0) # mean, std = [],[] # normalized_train_data=(data_train-np.mean(data_train,axis=0))/np.std(data_train,axis=0) #标准化 normalized_train_data = data_train train_x,train_y=[],[] #训练集x和y for i in range(len(normalized_train_data)-time_step): x=normalized_train_data[i:i+time_step,:13] # y=normalized_train_data[i+time_step:i+1+time_step,13,np.newaxis] y=normalized_train_data[i+time_step:i+1+time_step,13] train_x.append(x.tolist()) train_y.append(y.tolist()) mean, std = np.mean(train_y, axis=0), np.std(train_y, axis=0) train_x,train_y,mean,std = np.array(train_x), np.array(train_y),np.array(mean), np.array(std) train_x=(train_x-np.mean(train_x,axis=0))/np.std(train_x,axis=0) #标准化 train_y=(train_y-np.mean(train_y,axis=0))/np.std(train_y,axis=0) #标准化 return train_x,train_y,mean,std, y_
# 获得训练集的数据及其标签和batch_size print(data.shape) train_x, train_y, _, _,_= get_train_data(50, 0, 300) #这个50是我自己用的需要你们去调,time_step为20,即每一组数据长度为20 test_x, test_y, test_mean, test_std, test_y_= get_train_data(50, 300, 400) print(train_x.shape) print(train_y.shape) print(test_x.shape) print(test_y.shape) print(test_mean.shape) print(test_std.shape) print(test_y_.shape)
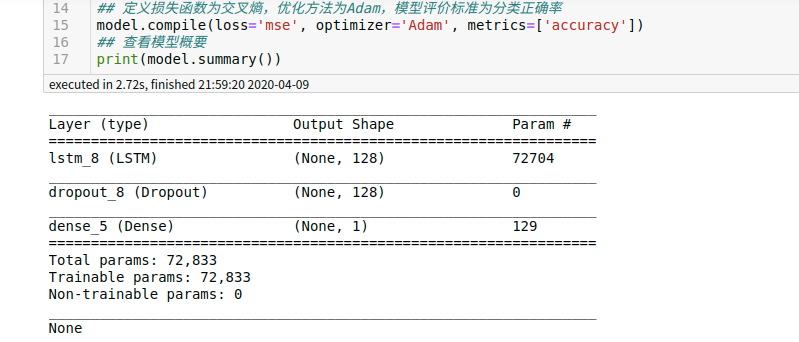
6. 构建神经网络(当然我弄的模型只是很简单的例子,需要你们自己去调整模型,包括损失函数为交叉熵,优化方法为Adam,模型评价标准这些都需要你们自己去调整,因为我的训练结果并不好):
## 初始化序列模型 model = Sequential() ## RNN层,在输入后的线性转换步骤添加随机失活,在循环阶段的线性转换也添加随机失活,失活概率都为0.2 model.add(LSTM(128, input_shape=(50, 13), dropout=0.2, recurrent_dropout=0.2, return_sequences=False)) model.add(Dropout(0.5)) # model.add(LSTM(64, dropout=0.2, recurrent_dropout=0.2, return_sequences=True)) # model.add(Dropout(0.5)) # model.add(LSTM(1, dropout=0.2, recurrent_dropout=0.2, return_sequences=False)) # model.add(Dropout(0.5)) # model.add(Flatten()) # model.add(Dense(1, activation='relu')) model.add(Dense(1)) ## 定义损失函数为交叉熵,优化方法为Adam,模型评价标准为分类正确率 model.compile(loss='mse', optimizer='Adam', metrics=['accuracy']) ## 查看模型概要 print(model.summary())
{kind=link}
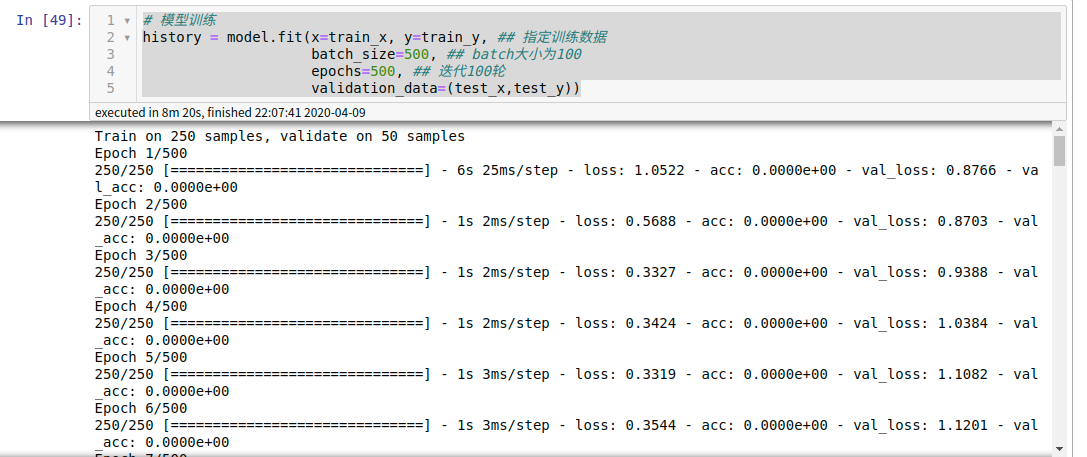
7. 模型训练
# 模型训练(这里面的参数需要你自己来调,我用的这些数据训练的结果并不好) history = model.fit(x=train_x, y=train_y, ## 指定训练数据 batch_size=500, ## batch大小为100 epochs=500, ## 迭代100轮 validation_data=(test_x,test_y))
{kind=link}
8. 用训练模型进行预测:
x, y, x_mean, y_std, y_label= get_train_data(50,465, 565) print(x.shape) print(x) print(x_mean.shape) print(y_std.shape) print(y_label.shape) # x = np.expand_dims(x, 1) result = model.predict(x, batch_size=1) print(result.shape) print(result) # result = result[0, 49, 0] # 将标准化的数据还原至真实数据值,并且计算测试集偏差 result=np.array(result)*y_std+x_mean print(result.shape) # 将标准化的数据还原至真实数据值,并且计算测试集偏差 # result=np.array(result)*test_std[13]+test_mean[13] # print(result) result = np.squeeze(result) print(y_std, x_mean) print(y_label) print(result)
9 . 折线图展示:
# 折线图展示 plt.figure(figsize=(300,150)) data_list=[str(i) for i in range(0, 50)] plt.plot(data_list[0:49], y_label[0:49], color='r', linewidth=15) plt.plot(data_list, result, color='b', linewidth=15) plt.xlabel('date') plt.ylabel('stock index') #plt.plot(list(range(len(test_predict))), test_predict, color='b') #plt.plot(list(range(len(test_y))), test_y, color='r') plt.show() 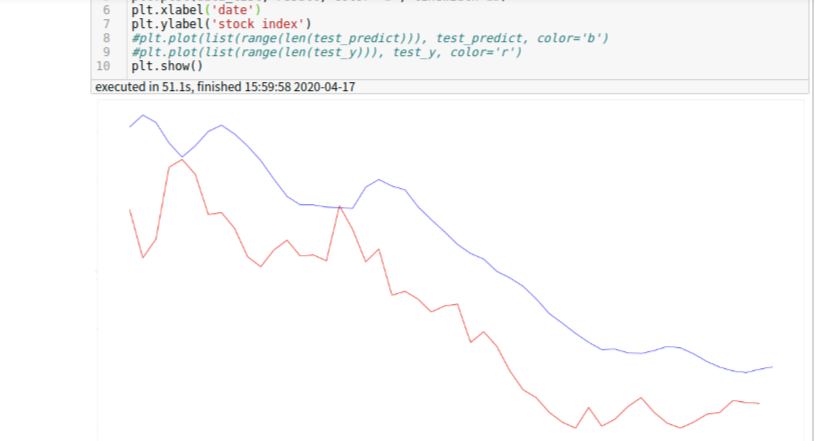{kind=link}
归纳总结:
本案例首先介绍了RNN、LSTM神经网络,再用Python实现了LSTM对股票收盘价的预测。
股价走势预测属于时间序列预测,数据为东阳光(sh600673)的收盘价。
主要使用的库为TensorFlow,是Python中常见的用于搭建神经网络的库。
而其它使用到的库有:多用于科学计算的NumPy库、常见于数据分析任务的Pandas库、负责绘图展示的Matplotlib库。
除本案例提到的库之外,还有sklearn库和keras库等机器学习常见的库,都是应该熟练掌握的库。
原文链接:https://www.qiquanji.com/post/160.html
本站声明:网站内容来源于网络,如有侵权,请联系我们,我们将及时处理。